

本系列课程旨在为大家介绍机器学习技术在商品期货中的应用,其他相关课程请点击下面链接:
导言
随着金融市场的不断发展,商品期货交易愈发复杂,而多因子模型成为分析市场的重要工具。在多因子模型中,决策树算法因其直观、易理解的特点逐渐受到关注。本文将深入探讨决策树算法在商品期货多因子模型中的应用,包括其原理、优点和缺点。
一、决策树算法原理
决策树是一种基于树状结构的模型,用于对数据集进行分类和回归分析。其核心思想是通过一系列规则对数据进行分割,最终达到对目标变量的精确预测。在商品期货多因子模型中,决策树可通过历史数据学习市场的规律,形成对未来价格走势的预测。
决策树的构建包括以下步骤:
- 特征选择:选择对模型影响较大的特征,以便更好地划分数据。
- 数据分割:根据选定的特征将数据集划分成不同的子集。
- 递归构建:对每个子集递归地应用上述步骤,构建出完整的决策树。
- 剪枝:为防止过拟合,对构建好的树进行剪枝操作,去除一些不必要的分支。
二、决策树算法优点
- 易解释性强: 决策树的图形化表达使得模型的解释变得非常直观,可以帮助交易者更好地理解市场走势的规律。
- 对缺失值不敏感: 决策树能够处理含有缺失值的数据,不需要对数据进行额外的处理。
- 适应多因子分析: 在多因子模型中,决策树能够同时考虑多个因子,更全面地捕捉市场变化。
三、决策树算法缺点
- 容易过拟合: 决策树容易在训练集上表现良好,但在新数据上表现较差,需要通过剪枝等手段防止过拟合。
- 不稳定性: 数据的微小变化可能导致树结构的显著改变,使得模型不够稳定。
- 处理连续性特征困难: 决策树对于连续性特征的处理相对较为困难,容易在连续数据上产生不准确的预测。
四、决策树算法在商品期货多因子模型中的应用
- 趋势判断: 通过历史价格、成交量等因子构建决策树,判断市场当前的趋势,为交易决策提供参考。
- 风险管理: 利用决策树对市场风险因素进行分析,制定相应的风险管理策略,降低交易风险。
- 交易信号生成: 基于决策树的模型,可以生成具体的交易信号,指导交易员进行买卖操作。
理论代码演示
本文使用2021到2023年8个品种的多因子数据进行决策树算法的演示,具体的代码逻辑如下所示:
-
导入库:导入所需的Python库,包括
pandas用于数据处理,numpy用于数值计算,train_test_split用于数据集划分,DecisionTreeClassifier用于构建决策树模型,accuracy_score用于评估模型准确性,以及GridSearchCV用于进行网格搜索。 -
读取数据:使用
pd.read_csv读取数据文件,这里将收益率定义为二分类变量。 -
提取因变量和因子:将数据集划分为因变量(
y)和因子(X),其中X是除了最后一列的所有列,而y是最后一列。 -
划分训练集和测试集:使用
train_test_split将数据集划分为训练集和测试集。 -
初始化决策树分类器:创建一个基本的决策树分类器。
-
设置待调参数:定义一个字典
param_grid,其中包含决策树模型的待调参数,例如最大深度、最小样本拆分数、最小样本叶子数等。 -
网格搜索调参:使用
GridSearchCV进行网格搜索,通过交叉验证找到最优参数组合。 -
获取最优参数:打印出找到的最优参数。
-
使用最优参数的模型进行预测:使用具有最优参数的模型进行测试集上的预测。
-
评估准确性:计算并打印模型在测试集上的准确性。
-
查看因子的重要性:获取最优模型的特征重要性。
-
绘制因子重要性图表:使用
matplotlib库绘制水平条形图,展示各个因子的相对重要性。
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('合成因子数据.csv', index_col = 0)
selFea = ['RollOver', 'Std',
'Skew', 'Kurt', 'PriceMom', 'VolumeMom', 'SpotPrice', 'ContractPrice',
'Receipt', 'ReceiptCng', 'basis', 'basisrate', 'br_5', 'br_22', 'br_63',
'br_126', 'br_243', 'wr_day', 'receipt_rolling_averages', 'wr_5',
'wr_22', 'wr_63', 'wr_126', 'wr_243', 'Returns']
df = data[selFea]
df = df.dropna()
# 处理因变量为01数据
df['Values'] = df['Returns'].apply(lambda x: 1 if x > 0 else 0)
df.drop('Returns', axis=1, inplace=True)
# 提取因变量和因子
X = df.drop('Values', axis=1) # X是所有除了最后一列的数据
y = df['Values'] # y是最后一列的数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化决策树分类器
clf = DecisionTreeClassifier()
# 设置待调参数
param_grid = {
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# 使用GridSearchCV进行调参
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 获取最优参数
best_params = grid_search.best_params_
print(f'最优参数:{best_params}')
# 使用最优参数的模型进行预测
best_clf = grid_search.best_estimator_
y_pred = best_clf.predict(X_test)
# 评估准确性
accuracy = accuracy_score(y_test, y_pred)
print(f'准确性:{accuracy}')
# 查看因子的重要性
feature_importances = best_clf.feature_importances_
# 绘制因子重要性图表
features = X.columns
indices = np.argsort(feature_importances)
plt.figure(figsize=(10, 6))
plt.barh(range(len(indices)), feature_importances[indices], align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Importance')
plt.title('Feature Importance')
plt.show()
最后的结果为:
最优参数:{'max_depth': 10, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'min_samples_split': 10}
准确性:0.5451713395638629
我们还对不同因子的有效性进行了排序,方便后续的因子选择。
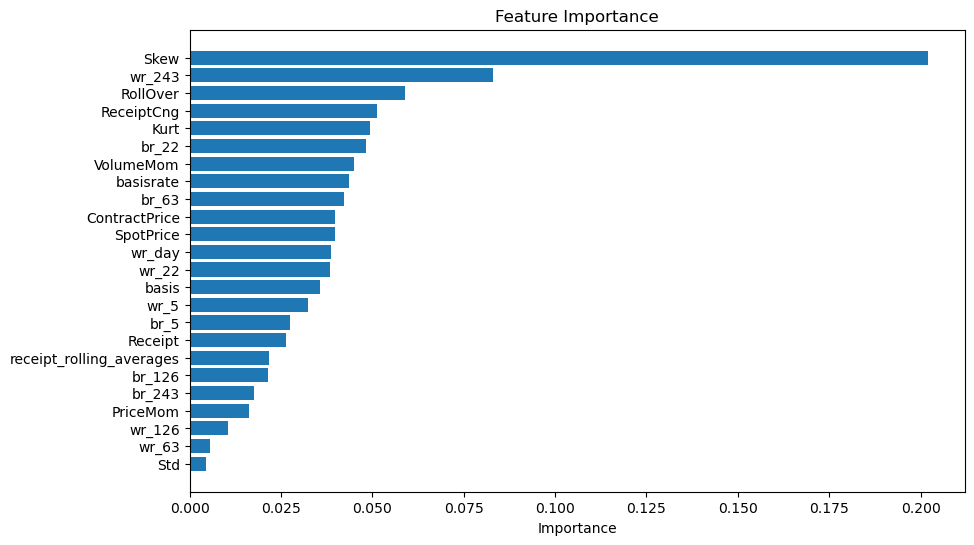
总体而言,该代码的目标是通过决策树模型对数据进行分类,并通过网格搜索找到最优参数。最后,通过绘制因子重要性图表,可以了解哪些因子对于模型的分类决策具有更大的影响。
多因子模型应用:因子选择
在了解完决策树算法的理论代码演示之后,我们就要引入函数模块进入多因子模型当中,相对于以前我们固定的设置因子,使用决策树算法我们可以实时动态的筛选和调整因子。首先我们整理上面的代码成为模版类库的模块函数:
python
# 因子选择
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
def get_top_features(data):
selFea = ['RollOver', 'Std', 'Skew', 'Kurt', 'PriceMom', 'VolumeMom', 'SpotPrice', 'ContractPrice',
'Receipt', 'ReceiptCng', 'basis', 'basisrate', 'br_5', 'br_22', 'br_63',
'br_126', 'br_243', 'wr_day', 'receipt_rolling_averages', 'wr_5', 'wr_22',
'wr_63', 'wr_126', 'wr_243', 'Returns']
df = data[selFea]
df = df.dropna()
# 处理因变量为01数据
df['Values'] = df['Returns'].apply(lambda x: 1 if x > 0 else 0)
df.drop('Returns', axis=1, inplace=True)
# 提取因变量和因子
X = df.drop('Values', axis=1) # X是所有除了最后一列的数据
y = df['Values'] # y是最后一列的数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化决策树分类器
clf = DecisionTreeClassifier()
# 设置待调参数
param_grid = {
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# 使用GridSearchCV进行调参
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 获取最优参数
best_params = grid_search.best_params_
best_clf = grid_search.best_estimator_
y_pred = best_clf.predict(X_test)
feature_importances = best_clf.feature_importances_
# 获取排名前8的features名称
top_features_indices = np.argsort(feature_importances)[-8:]
top_features = X.columns[top_features_indices]
return top_features.tolist()
ext.get_top_features = get_top_features
接下来在多因子模型当中,我们在进行因子合成之前,使用上面的模块函数代码进行因子的选择:
python
## 因子计算
caldf = ext.calFactor(factordf)
Log('因子计算完成#ff0000')
## 因子处理
prodf = ext.proFactor(caldf)
Log('因子处理完成#ff0000')
## 因子选择
selFea = ext.get_top_features(prodf)
Log('因子选择:', selFea)
## 因子合成
comdf = ext.getComposite(prodf, selFea)
finaldf = comdf[comdf.Time == cur_time]
Log('因子合成完成#ff0000')
## 多空组判断
positive_codes = ext.groupFactor(finaldf, 'HeCompositeFactor')[0]
negative_codes = ext.groupFactor(finaldf, 'HeCompositeFactor')[1]
Log('多空组判断完成#ff0000')
Log('做多组:', positive_codes)
Log('做空组:', negative_codes)
## 交易操作
ext.trade(positive_codes, negative_codes)
我们来看下回测结果:

可以看到,在因子处理完成之后,我们可以使用决策树算法进行因子的动态筛选,方便挑选出来具有显著性的因子,后续进行因子合成,从而提高模型的拟合能力。
结论
决策树算法作为一种强大的数据分析工具,在商品期货多因子模型中展现出广阔的应用前景。通过深入理解决策树的原理、优点和缺点,交易者可以更加灵活地运用该算法,更好地把握市场脉搏,实现更稳健的投资策略。然而,在应用过程中,也需要注意克服其过拟合和不稳定性等缺点,以确保模型的鲁棒性和可靠性。
本系列课程旨在为大家介绍机器学习技术在商品期货量化交易中的应用,其他相关文章请点击下面链接:
- 1