

相关性计算在商品期货量化分析中的应用及Python实现
一、引言
在数据分析中,相关性是衡量两个变量之间关联程度的重要工具。商品期货市场中的价格、交易量等众多因素之间存在一定的关联,因此相关性计算在商品期货量化分析中扮演着至关重要的角色。本文将介绍相关性计算的各种方法及其在商品期货量化分析中的应用,并使用Python代码进行实现。
二、相关性计算方法
1. 皮尔逊相关系数(Pearson Correlation Coefficient)
概念:皮尔逊相关系数是一种衡量两个变量之间线性相关程度的统计量,值域为[-1,1]。
计算公式:
$\rho_{XY} = \frac{Cov(X, Y)}{\sigma_X \sigma_Y}$
优缺点:
- 优点:计算简单,能反映线性相关程度。
- 缺点:对非线性关系不敏感。
2. 斯皮尔曼秩相关系数(Spearman's Rank Correlation Coefficient)
概念:斯皮尔曼秩相关系数是一种衡量两个变量之间单调关系程度的统计量,值域为[-1,1]。
计算公式:
$r_s = 1 - \frac{6 \sum_{i=1}^{n} d_i^3}{n(n^2 - 1)}$
优缺点:
- 优点:对非线性关系较敏感,对异常值不敏感。
- 缺点:计算相对复杂。
3. 肯德尔秩相关系数(Kendall's Tau)
概念:肯德尔秩相关系数是一种衡量两个变量之间排序关系一致性的统计量,值域为[-1,1]。
计算公式:
$\tau = \frac{2(P - Q)}{n(n - 1)}$
优缺点:
- 优点:对非线性关系较敏感,对异常值不敏感。
- 缺点:计算相对复杂。
4. 距离相关性(Distance Correlation)
概念:距离相关性是一种用于度量变量之间关系的方法,特别适用于非线性关系。
计算公式:
$R(X, Y) = \frac{cov(d(X), d(Y))}{\sqrt{cov(d(X), d(X)) \cdot cov(d(Y), d(Y))}}$
优缺点:
- 优点:对于非线性关系更敏感,能捕捉到数据点之间的空间结构。
- 缺点:计算复杂度较高,需要计算所有数据点之间的距离;对异常值敏感,如果数据中存在异常值。
三、相关性计算在商品期货量化分析中的重要性
在商品期货市场中,相关性计算在以下方面具有重要作用:
- 投资组合优化:通过分析不同期货品种之间的相关性,可以构建具有较低风险的投资组合。
- 套利策略:利用相关性分析,可以发现价格偏离的期货合约,从而实施套利策略。
- 价格预测:通过分析历史价格数据与其他相关因素的相关性,可以预测未来价格走势。
- 风险管理:通过监测期货市场与其他金融市场之间的相关性,可以及时发现并管理潜在风险。
四、Python实现相关性计算
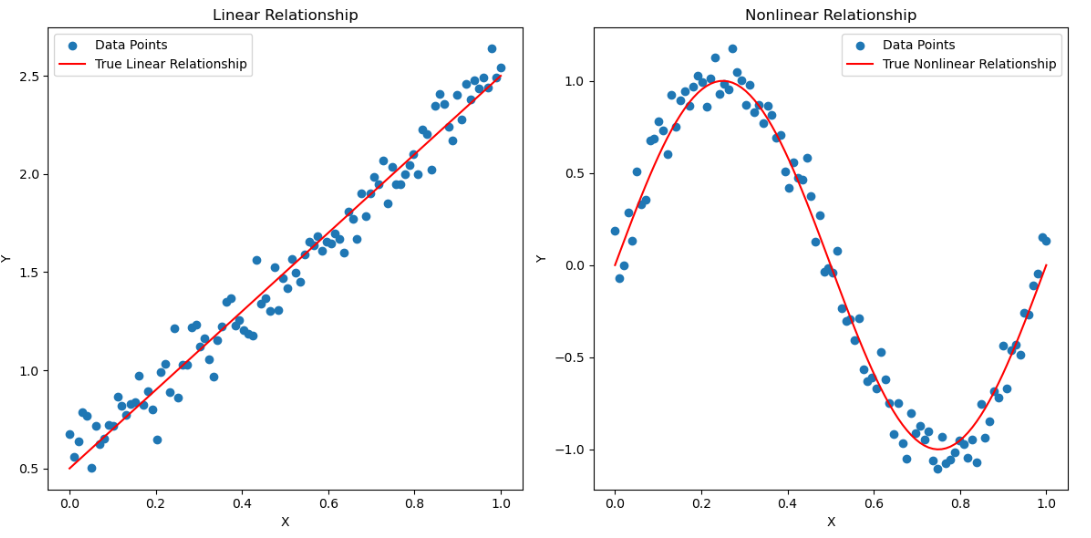
这里我们分别生成一个线性关系的x和y,和非线性关系的x和y,进行一下四种相关系数的展示和计算。
python
import numpy as np
import matplotlib.pyplot as plt
# 生成线性关系的示例数据
np.random.seed(0)
x_linear = np.linspace(0, 1, 100)
y_linear = 2 * x_linear + 0.5 + np.random.normal(0, 0.1, 100)
# 生成非线性关系的示例数据
x_nonlinear = np.linspace(0, 1, 100)
y_nonlinear = np.sin(2 * np.pi * x_nonlinear) + np.random.normal(0, 0.1, 100)
# 画图
plt.figure(figsize=(12, 6))
# 线性关系图
plt.subplot(1, 2, 1)
plt.scatter(x_linear, y_linear, label="Data Points")
plt.plot(x_linear, 2 * x_linear + 0.5, color='red', label="True Linear Relationship")
plt.title("Linear Relationship")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
# 非线性关系图
plt.subplot(1, 2, 2)
plt.scatter(x_nonlinear, y_nonlinear, label="Data Points")
plt.plot(x_nonlinear, np.sin(2 * np.pi * x_nonlinear), color='red', label="True Nonlinear Relationship")
plt.title("Nonlinear Relationship")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
plt.tight_layout()
plt.show()
具体的相关系数计算代码如下所示,首先导入具体的包,然后开展计算。
python
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import pearsonr, spearmanr, kendalltau
import dcor
# 计算线性关系数据的相关系数及p值
pearson_corr_linear, pearson_p_value_linear = pearsonr(x_linear, y_linear)
spearman_corr_linear, spearman_p_value_linear = spearmanr(x_linear, y_linear)
kendall_corr_linear, kendall_p_value_linear = kendalltau(x_linear, y_linear)
distance_corr_linear = dcor.distance_correlation(x_linear, y_linear)
# 计算非线性关系数据的相关系数及p值
pearson_corr_nonlinear, pearson_p_value_nonlinear = pearsonr(x_nonlinear, y_nonlinear)
spearman_corr_nonlinear, spearman_p_value_nonlinear = spearmanr(x_nonlinear, y_nonlinear)
kendall_corr_nonlinear, kendall_p_value_nonlinear = kendalltau(x_nonlinear, y_nonlinear)
distance_corr_nonlinear = dcor.distance_correlation(x_nonlinear, y_nonlinear)
# 打印结果
print("Linear Relationship:")
print(f"Pearson correlation: {pearson_corr_linear}, p-value: {pearson_p_value_linear}")
print(f"Spearman correlation: {spearman_corr_linear}, p-value: {spearman_p_value_linear}")
print(f"Kendall correlation: {kendall_corr_linear}, p-value: {kendall_p_value_linear}")
print(f"Distance correlation: {distance_corr_linear}, p-value: Not applicable")
print("\nNonlinear Relationship:")
print(f"Pearson correlation: {pearson_corr_nonlinear}, p-value: {pearson_p_value_nonlinear}")
print(f"Spearman correlation: {spearman_corr_nonlinear}, p-value: {spearman_p_value_nonlinear}")
print(f"Kendall correlation: {kendall_corr_nonlinear}, p-value: {kendall_p_value_nonlinear}")
print(f"Distance correlation: {distance_corr_nonlinear}, p-value: Not applicable")
具体的计算结果如下所示
Linear Relationship:
Pearson correlation: 0.9850653691066418, p-value: 1.0917357327342142e-76
Spearman correlation: 0.9862826282628263, p-value: 1.743339101348145e-78
Kendall correlation: 0.901818181818182, p-value: 2.497554911373763e-40
Distance correlation: 0.9838927310804086, p-value: Not applicable
Nonlinear Relationship:
Pearson correlation: -0.7597985716030917, p-value: 4.980631737318943e-20
Spearman correlation: -0.74016201620162, p-value: 1.3858022143073908e-18
Kendall correlation: -0.5103030303030304, p-value: 5.3647003404031073e-14
Distance correlation: 0.838532484798885, p-value: Not applicable
可以看到,对于高度线性相关的数据,四种算法都可以得出较高的相关分数;但是对于非线性相关关系的数据,只有距离相关的算法可以得出较高的正向相关分数。
五、优宽平台应用:双品种实时相关展示
众所周知,商品期货市场有很多具有较高相关性的品种,通过实时检测两品种的相关关系,可以实时了解价格走势的动态。下面的代码,在优宽平台通过比较两个商品合约('rb888'和'hc888')的每日收盘价数据,分析它们之间的三种相关性和距离相关性数值的大小。
代码解释
prebartime:用于跟踪上一个收盘时间,以确保只在新的交易日执行一次分析。while True循环:无限循环,持续获取和分析市场数据。exchange.SetContractType:设置合约类型为'rb888'和'hc888'。exchange.GetRecords(PERIOD_D1):获取每日价格记录。maxLen:计算两个合约数据的最小长度,以确保数组大小一致。- 数据判断条件:检查两个合约的最新交易时间是否相同,且为新的交易日。
- 提取收盘价数据:截取收盘价数据并转为NumPy数组。
- 相关性分析:使用Pearson、Spearman、Kendall和距离相关性计算两个品种之间的相关性。
- 结果打印:打印相关性系数和p值。
import numpy as np
from scipy.stats import pearsonr, spearmanr, kendalltau
import dcor
def main():
prebartime = 0
while True:
exchange.SetContractType('rb888')
r_rb = exchange.GetRecords(PERIOD_D1)
exchange.SetContractType('hc888')
r_hc = exchange.GetRecords(PERIOD_D1)
maxLen = min(len(r_rb), len(r_hc))
if r_rb[-1].Time == r_hc[-1].Time and r_rb[-1].Time != prebartime:
cur_rb = np.array(r_rb.Close[-maxLen : -1])
cur_hc = np.array(r_hc.Close[-maxLen : -1])
# 计算两个品种的相关系数及p值
pearson_corr, pearson_p_value = pearsonr(cur_rb, cur_hc)
spearman_corr, spearman_p_value = spearmanr(cur_rb, cur_hc)
kendall_corr, kendall_p_value = kendalltau(cur_rb, cur_hc)
distance_corr = dcor.distance_correlation(cur_rb, cur_hc)
# 打印结果
Log(f"Pearson correlation: {pearson_corr}, p-value: {pearson_p_value}")
Log(f"Spearman correlation: {spearman_corr}, p-value: {spearman_p_value}")
Log(f"Kendall correlation: {kendall_corr}, p-value: {kendall_p_value}")
Log(f"Distance correlation: {distance_corr}, p-value: Not applicable")
prebartime = r_rb[-1].Time
ext.PlotLine("Pearson correlation", pearson_corr)
ext.PlotLine("Spearman correlation", spearman_corr)
ext.PlotLine("Kendall correlation", kendall_corr)
ext.PlotLine("Distance correlation", distance_corr)
Sleep(1000*60*60*24)
根据返回的图像,可以实时看到两个品种的四个相关算法计算出来的数值,其中前三个算法数值计算的是比较一致的,最后距离相关计算的算法数值具有显著差异,证明这两个品种之间的关系更倾向于是线性关系。
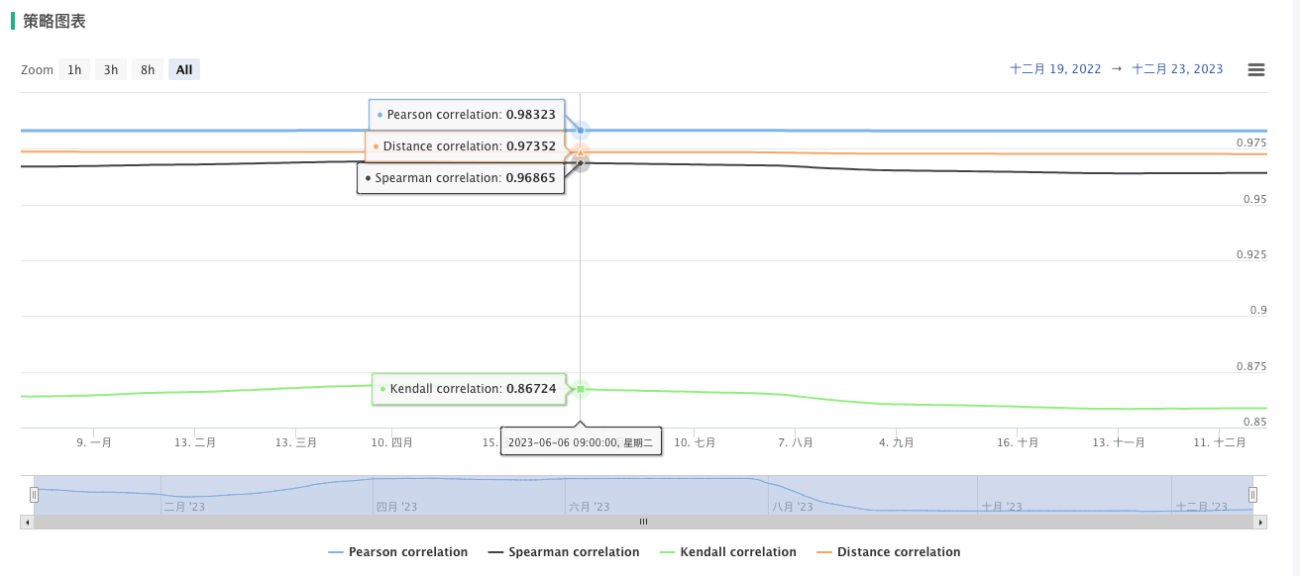
通过上述的代码呢,可以实时展示出来两个品种之间的相关性,我们可以在不同商品合约之间寻找潜在的市场机会或风险,并提供有关其相关性的实时信息。
六、结论与展望
本文详细介绍了相关性计算的各种方法及其在商品期货量化分析中的应用,并使用Python代码进行了实现。相关性计算在投资组合优化、套利策略、价格预测和风险管理等方面具有重要作用。未来可以进一步研究不同相关性计算方法在商品期货市场分析中的效果,以期为投资决策提供更多有益信息。
本系列课程旨在为大家介绍机器学习技术在商品期货量化交易中的应用,其他相关文章请点击下面链接:
- 1