
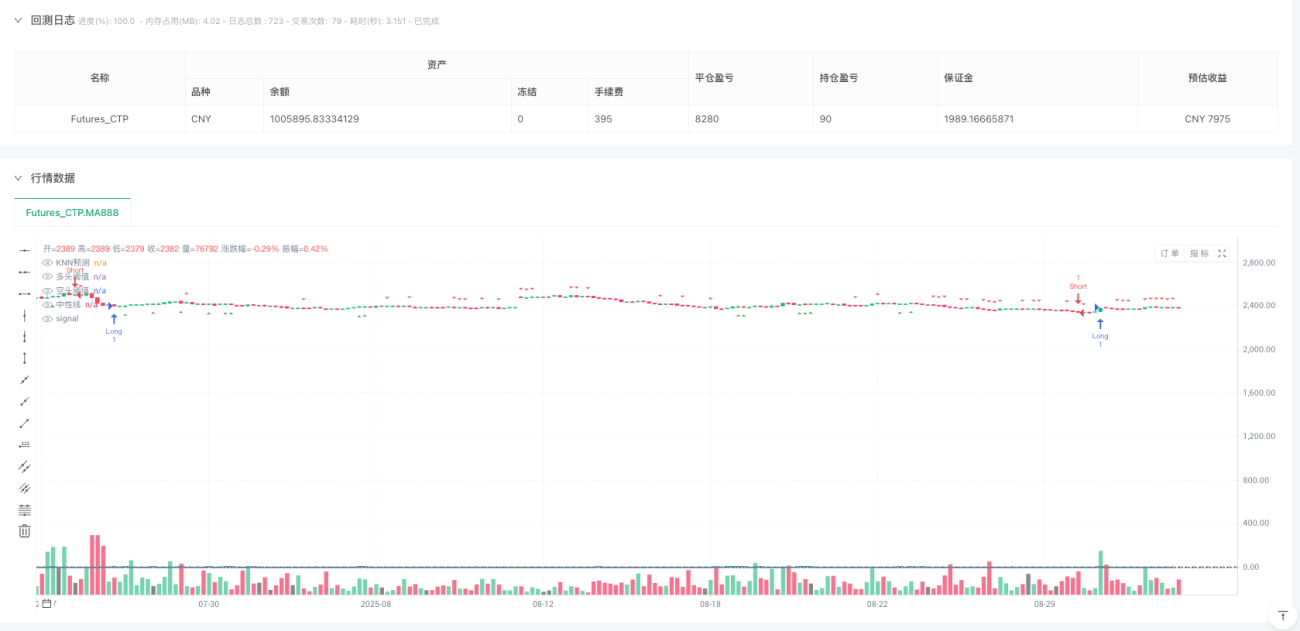
为什么传统技术分析需要机器学习的加持?
在量化交易领域摸爬滚打多年,我发现一个有趣的现象:大多数交易者仍在使用几十年前的技术指标,却期望在瞬息万变的市场中获得超额收益。这就像用算盘去解决微积分问题——工具本身没有问题,但效率和精度已经跟不上时代了。
今天要分析的这个高级KNN(K-近邻)交易策略,恰恰代表了量化交易的一个重要发展方向:将机器学习算法与传统技术分析相结合,构建更智能的交易决策系统。
什么是KNN算法,为什么它适合金融预测?
KNN算法的核心思想极其简单却又深刻:相似的市场环境往往产生相似的价格走势。这个假设在金融市场中有着坚实的理论基础——市场参与者的行为模式具有一定的重复性和可预测性。
该策略的特色在于构建了一个七维特征空间:
- 价格动量:衡量价格变化的速度和方向
- RSI指标:反映超买超卖状态
- 成交量比率:揭示资金流向变化
- 波动率:量化市场情绪波动
- 趋势强度:通过双均线系统识别趋势
- MACD特征:捕捉动量转换信号
- 布林带位置:判断价格相对位置
如何实现特征工程的标准化处理?
这里有一个关键的技术细节值得深入探讨:特征标准化。策略使用Z-score标准化方法,将所有特征转换到相同的数值范围内。这一步骤至关重要,因为:
- 消除量纲影响:价格、成交量、RSI等指标的数值范围差异巨大
- 提高算法效率:标准化后的欧几里得距离计算更加准确
- 增强模型稳定性:避免某个特征因数值过大而主导整个预测过程
normalize(src, length) =>
mean_val = ta.sma(src, length)
std_val = ta.stdev(src, length)
std_val == 0 ? 0.0 : (src - mean_val) / std_val
距离加权预测:为什么近邻的"远近"很重要?
传统的KNN算法通常采用简单投票机制,但这个策略采用了更精妙的距离加权方法。距离越近的历史样本,其预测权重越高。这种设计反映了一个重要的金融市场特征:市场状态的相似度是连续的,而非离散的。
权重计算公式:weight = 1.0 / (distance + 0.001)
这种加权机制能够:
- 更精确地反映历史相似度
- 减少噪声数据的干扰
- 提高预测结果的可靠性
什么情况下这个策略表现最佳?
基于我对机器学习交易策略的研究经验,KNN策略在以下市场环境中通常表现较好:
- 趋势性市场:当市场存在明显趋势时,历史相似模式更容易重现
- 中等波动率环境:过高或过低的波动率都会影响特征的稳定性
- 流动性充足的品种:确保技术指标的有效性和交易执行的顺畅
需要注意的是,该策略设置了较为保守的风险管理参数:2%止损,4%止盈,这种1:2的风险收益比体现了策略设计者对风险控制的重视。
策略的创新点与潜在改进方向
这个策略的几个创新之处值得称赞:
- 多维特征融合:不依赖单一指标,而是构建综合特征体系
- 动态历史窗口:通过滑动窗口机制保持数据的时效性
- 概率化输出:提供预测概率而非简单的买卖信号
但同时,我也看到了一些改进空间:
- 特征选择优化:可以引入特征重要性评估,动态调整特征权重
- 参数自适应:K值和阈值可以根据市场状态动态调整
- 多时间框架融合:结合不同周期的信号可能提高预测准确性
实际应用中的注意事项
在实盘应用中,需要特别关注以下几点:
- 计算复杂度:KNN算法的计算量随历史数据增加而增长,需要平衡精度与效率
- 过拟合风险:过小的K值可能导致过拟合,过大则可能欠拟合
- 数据质量:异常数据点会显著影响距离计算,需要建立数据清洗机制
结语:机器学习量化交易的未来
这个KNN策略代表了量化交易发展的一个重要方向:从简单的规则驱动转向智能的数据驱动。虽然机器学习不是万能的,但它为我们提供了一种更科学、更系统的方法来理解和预测市场行为。
在我看来,未来的量化交易将是传统金融理论、现代统计学和机器学习技术的深度融合。这个KNN策略只是一个开始,更多的创新和突破还在路上。
- 1