

再次叠甲,本文只是尝试使用高频因子进行盘口价格预测的探索,距离真正工业级别的高频策略还有不少的差距,各位量化大佬请提出宝贵的建议。
在上节课的基础上,我们根据盘口的五档数据创建了买卖压力指标,交易量订单流不平衡,订单不平衡,深度不平衡,和价差五个示范指标,本次呢,我们就来使用这五个指标,并结合交易量增量,持仓增量,一共七个指标,尝试使用不同的采样频率,结合各类的机器学习算法,用来尝试预测价格涨跌。
(chart/2c305a69-ac0c-4359-8dbb-4ec948344a8e)
高频因子采样
第一步,我们将对高频因子进行不同降频的处理,以观察在不同切片粒度下,高频因子与价格涨跌之间的关系。这将帮助我们更全面地理解这些因子在不同时间尺度上与价格变动之间的潜在关联,从而提供更深入的市场行为分析和决策支持。
全采样处理
盘口数据更新的频率是每秒2个tick左右,我们可以利用全采样的数据来预测tick级别价格的涨跌,我们来观察一下tick级别的因子数据和下期tick涨跌之间的关系。
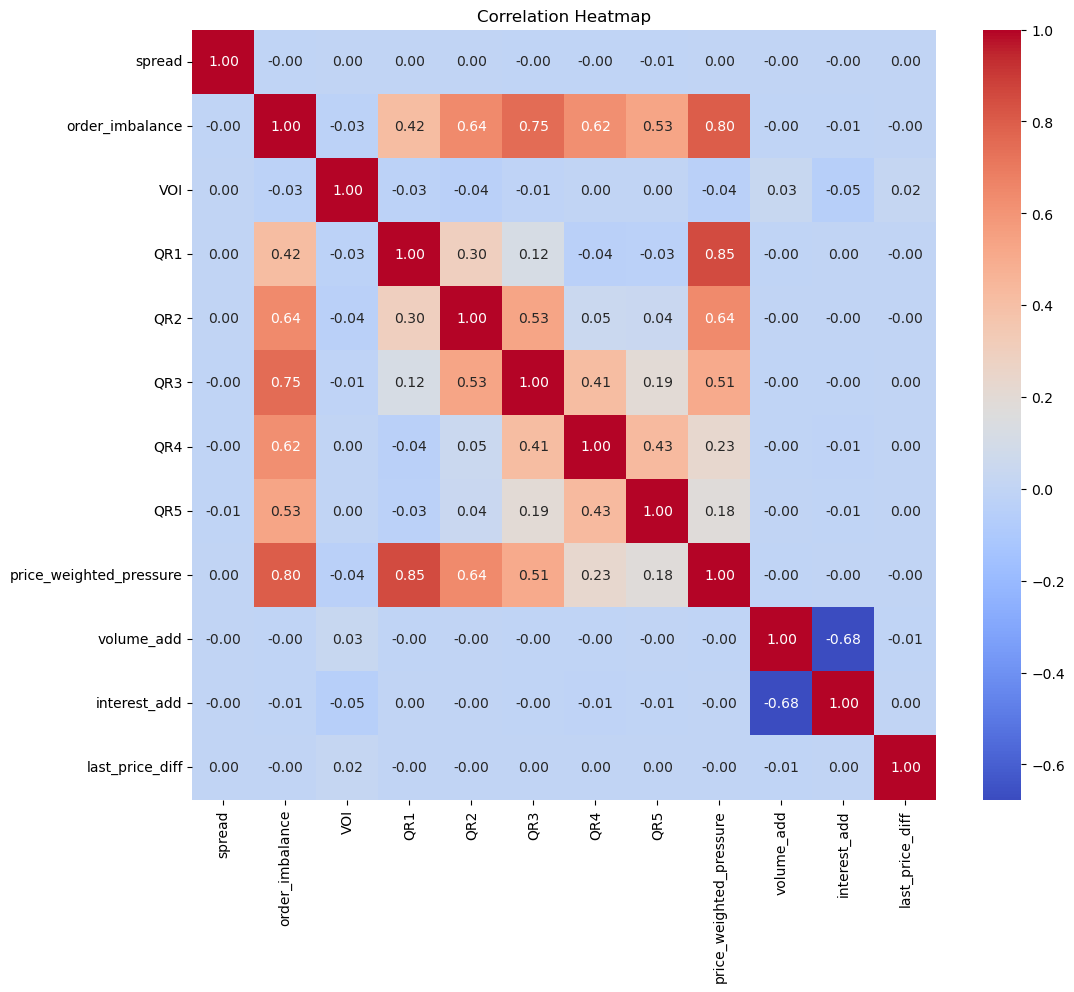
可以看到,全采样的高频因子和价格涨跌的相关关系处于较低的水平,这可能是因为tick更新的较快,而大部分的时间都处于随机波动的时间,所以有很多无效的干扰波动。
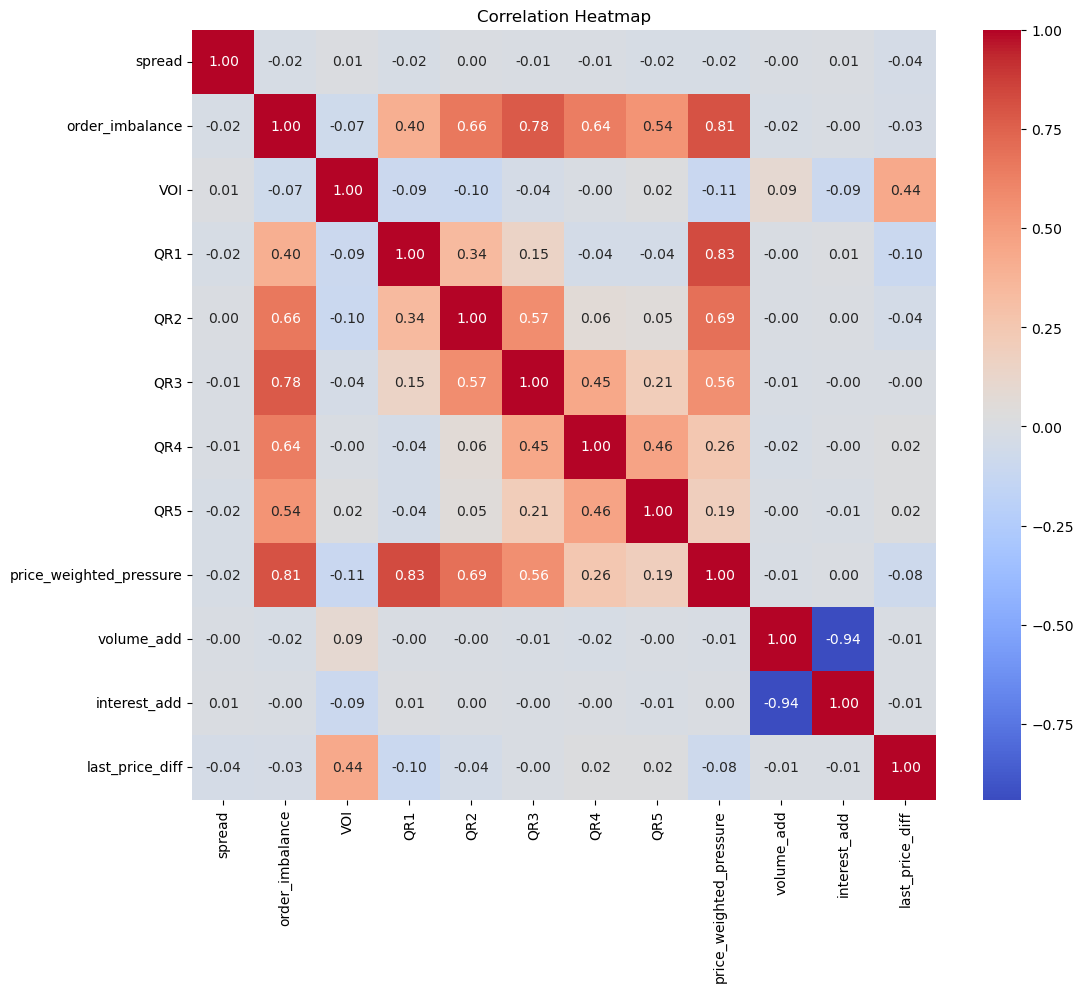
10秒均值采样
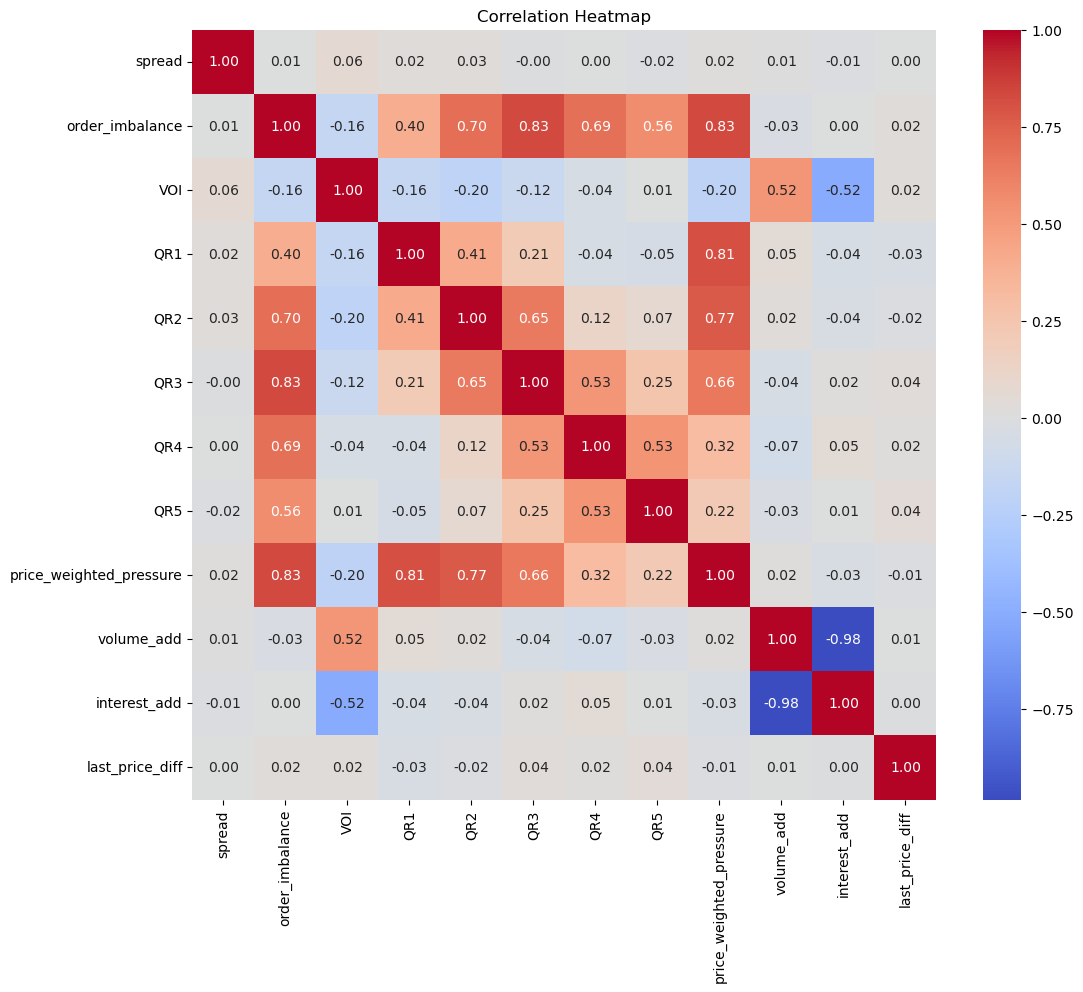
使用Pandas的resample函数,我们可以获取10秒的采样频率,可以发现高频因子和价格涨跌的相关性确实有了一定的提升。特别是VOI(交易量订单流不平衡)与价格涨跌达到了0.44的相关性。
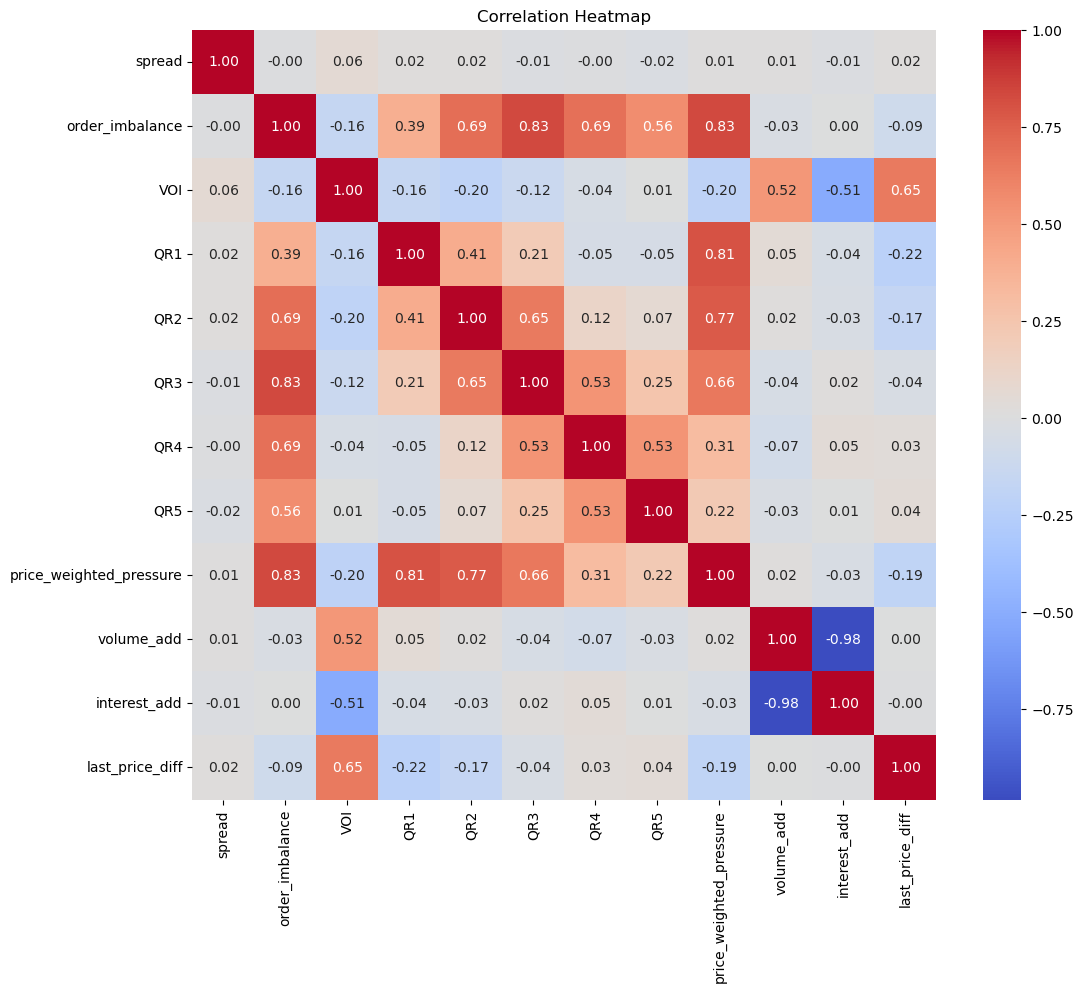
分钟级别均值采样
对于分别级别的采样频率,可以看到高频因子和价格涨跌的相关性得到了很大的提升。似乎在一定程度上,信息损失的越多,高频因子和价格涨跌的相关性越强。当然这里的相关关系是线性的相关关系。
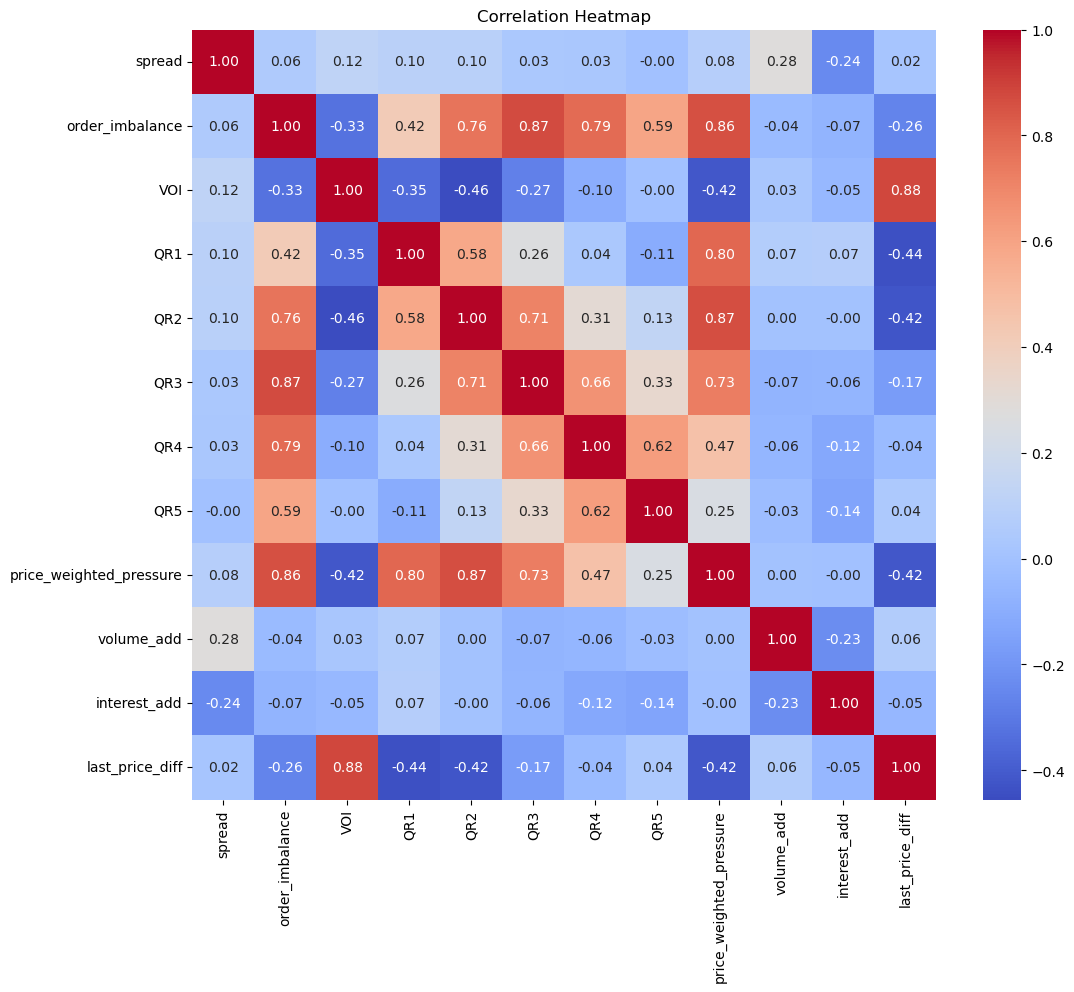
另外,如果我们想查看是否具有较高的涨跌幅绝对值和盘口因子的相关性最大,可以进行数据筛选(涨跌绝对值>=4,因为纸浆品种一跳为2点,索引两个涨跌绝对值为4点),结果显示价格涨跌和盘口因子相关性得到加强。
这里需要注意的是,第一,这里降频采样的方法是使用采样周期内的均值,另外大家可以尝试自定义的采样方法(例如取变异系数[均值/标准差])等验证相关关系;第二,这里我们计算相关为周期内的均值和周期内涨幅之间的相关性,如想探索周期内均值与下期周期价格涨跌的预测关系,需将预测变量进行偏移处理。我们举例示范一下,结果显示预测的线性相关性得到大大的降低,
高频因子预测价格涨跌
在对高频因子和价格涨跌进行不同采样频率的线性相关性探索后,我们观察到它们之间的线性相关性可能相对较弱。因此,除了传统的线性回归算法之外,我们决定使用分钟级别的数据,尝试机器学习算法,包括K最近邻(KNN)、支持向量机(SVM)和梯度提升树(GBT),用来比较不同算法对性能的影响,并探究是否可以获得更好的预测效果。
价格的涨跌是一个连续的变量,但是对于期货操作来说,具有开多(盘口价格上升),开空(盘口价格下降),空仓(盘口价格不变)三种操作。因此,对于下面的线性回归算法,我们使用原始的价格涨跌数据;对于机器学习的算法(KNN,SVM和GBT),我们对价格涨跌进行三分类的处理:价格上涨定义为1(多头入场),价格下跌定义为-1(空头入场),价格不变定义为0(无交易操作)。
线性回归
线性回归是一种基本的回归分析方法,用于建立自变量与因变量之间的线性关系。在这个场景中,我们尝试使用线性回归算法预测价格涨跌的幅度。
python
import statsmodels.api as sm
def build_ols_model(df):
# 从数据框中选择特征和目标变量
df = df.dropna()
features = ['spread', 'order_imbalance', 'VOI', 'QR1', 'QR2', 'QR3', 'QR4', 'QR5', 'price_weighted_pressure','volume_add', 'interest_add']
target = 'last_price_diff'
X = df[features]
y = df[target]
# 添加截距项
X = sm.add_constant(X)
# 建立OLS模型
model = sm.OLS(y, X).fit()
# 打印模型结果
print(model.summary())
build_ols_model(secDf)
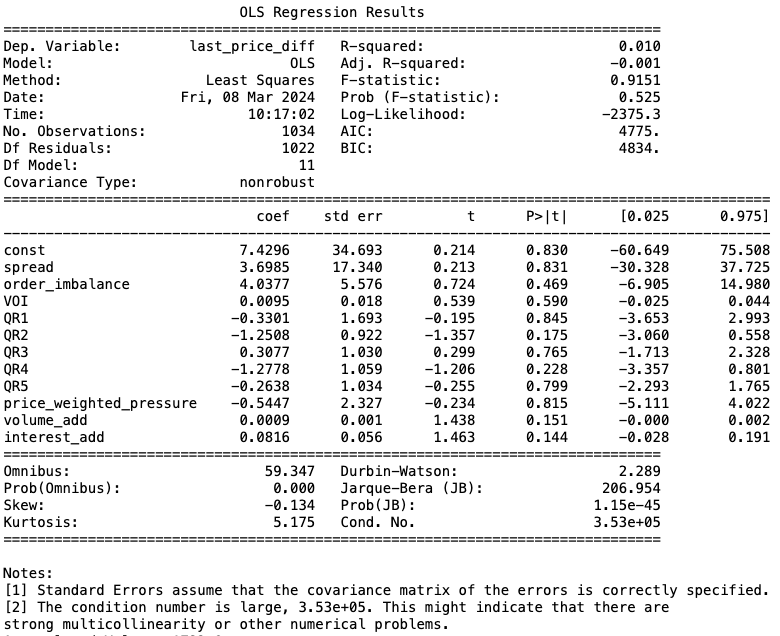
不出意料,线性回归分析获得了较低的预测结果(R-squared = 0.01),这证明了高频盘口因子和盘口涨跌幅度的线性相关性确实较弱,下面我们来使用机器学习的算法进行非线性关系的探索。
K最近邻
K最近邻是一种基于实例的学习方法,根据最近邻的标签进行分类。在这里,我们使用KNN算法对价格涨跌进行分类,考虑数据点周围的邻居来做出决策。
python
secDf.dropna(inplace= True)
features = ['spread', 'order_imbalance', 'VOI', 'QR1', 'QR2', 'QR3', 'QR4', 'QR5', 'price_weighted_pressure','volume_add', 'interest_add']
X = secDf[features]
secDf['last_price_diff_multi'] = secDf['last_price_diff'].apply(lambda x: 1 if x > 0 else (-1 if x < 0 else 0))
y = secDf['last_price_diff_multi']
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
knn_classifier = KNeighborsClassifier(n_neighbors=10)
knn_classifier.fit(X_train_scaled, y_train)
predY = knn_classifier.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
根据参数调试的结果,在n_neighbors设置为10的时候,获取到了较高的预测争取率,达到0.34,但是我们更加关注的是算法的模拟回测效果。因此,我们定义一个理想化的交易仿真过程(不考虑滑点和市场冲击):
- 如果预测结果和真实结果,同样均为开多或者开空方向(1或者-1),那么获取到利润为:涨跌幅的收益-开仓手续费(10元)。
- 如果预测结果和真实结果不一致,并且预测结果不等于0(需要进行操作),那么获取到的损失为:涨跌幅的损失-开仓手续费(10元)。
- 其他情况,预测结果为0,不进行操作,无论预测正确或者错误,都不会造成任何盈利或者损失。
python
realY = y_test.tolist()
predY = y_pred.tolist()
yValue = treeDF['last_price_diff'][y_test.index].tolist()
accumulated_value = 0
for real, pred, y_value in zip(realY, predY, yValue):
# 如果realY和predY一致,将yValue的绝对值累加
if real == pred == 1 or real == pred == -1:
print('成功,盈利:', abs(y_value) * 20 - 10)
accumulated_value += abs(y_value) * 20 - 10
# 如果realY和predY不一致,将yValue的绝对值减去
elif real != pred and pred !=0:
accumulated_value -= abs(y_value) * 20 + 10
print('失败,损失:', -abs(y_value) * 20 - 10)
经过仿真交易模拟,在考虑手续费的情况下,收益为-300元;不考虑手续费的情况下,收益为280元。看来手续费确实是高频策略的天敌。
| 算法 | 仿真收益(考虑手续费) | 仿真收益(不考虑手续费) |
|---|---|---|
| KNN | -300 | 280 |
支持向量机
支持向量机是一种强大的分类算法,可以处理线性和非线性关系。在这个任务中,我们尝试使用SVM对价格涨跌进行分类。
python
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
param_grid = {'kernel': ['linear', 'rbf', 'poly', 'sigmoid']}
svm_classifier = SVC()
grid_search = GridSearchCV(svm_classifier, param_grid, cv=5, scoring='precision_weighted')
grid_search.fit(X_train_scaled, y_train)
best_params = grid_search.best_params_
best_svm_classifier = grid_search.best_estimator_
y_pred = best_svm_classifier.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
结果显示,正确率和K最近邻相差并不多,为0.325,但是模拟回测(不考虑手续费)的结果为-160元,收益转为负值。
| 算法 | 仿真收益(考虑手续费) | 仿真收益(不考虑手续费) |
|---|---|---|
| KNN | -300 | -160 |
我们可以对模拟预测结果进行频率分析,可以看到SVM算法更多的倾向于将结果预测为0,减少了更多的操作,随之收益率也降低。
| 算法 | 开多分类 | 空仓分类 | 开空分类 |
|---|---|---|---|
| KNN | 25 | 46 | 33 |
| SVM | 9 | 90 | -5 |
梯度提升树
梯度提升树是一种集成学习方法,通过组合多个决策树来提高性能。在这里,我们使用GBT算法来学习价格涨跌的模式。根据参数的调试,对测试集的最优模型预测正确率达到0.288,模拟回测的结果在不考虑手续费的情况下达到360元。
python
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(random_state=3)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
| 算法 | 仿真收益(考虑手续费) | 仿真收益(不考虑手续费) |
|---|---|---|
| GBT | -60 | 360 |
如果要说哪个算法性能最好,暂时是无法是下结论的,因为目前数据量确实较少(只有一周的数据),因此对于测试集选择的随机性就很大,所以模型的性能是不稳定的,本文更多提供的是一个盘口高频因子预测的框架。其实这里面可以优化,深挖和改进的地方还有很多,希望在后续的学习当中可以继续完善。
本系列课程旨在为大家介绍高频交易在商品期货量化交易中的应用,其他相关文章请点击下面链接:
- 1